Parallel programming
Contents:
- Introduction and theory
- Parallelising a for loop
- Using
rayonand iterables to make this much easier - Which work to parallelise?
This chapter covers the fundamentals in parallelism and implementation in rust. Subsections are then available covering examples in python, R and more complex examples in rust.
Using multiple CPU cores is a very common optimisation strategy. Modern laptops have 4-10 cores, and HPC nodes usually have 32. These give the best case speedups, though often efficiency \(\frac{t_{\mathrm{serial}}}{t_{\mathrm{parallel}} \times N_{\mathrm{CPUs}}}\) is less than 100% due to overheads of setting up parallelisation, such as spawning threads.
Introduction and theory
Some analysis does not require any use of shared memory or communication between threads. For example running the same program such as a genome assembler on 1000 different samples can be run as 1000 totally separate processes, and is probably best done as a job array or a pipeline like snakemake. These are known as 'embarrassingly parallel' tasks. You can also multithread embarrassingly parallel tasks when you are writing software, as it will be easier for many users to take advantage of.
What are good candidates for multithreading within a process? Usually where you have a part of your code that is particularly computationally intensive (usually as identified by some profiling) and uses the same variables/objects and therefore shared memory as the rest of the process.
When is it less likely to work? If multiple threads might write to the same variable or use the same resource then this makes things more complicated and often slower (but you can use atomic operations or mutexes to make this work). Additionally, making new threads usually has an overhead i.e. time cost, so the process being parallelised usually needs to run for a reasonable amount of time (at least greater than the cost of starting a new thread).
A common structure in code that can be parallelised is a for loop where each
iteration takes a non-negligible amount of time, as long as the loops do not
depend on each other. Where the results need combining, a common approach is
'map-reduce' which applies a function to multiple data using map then applies
a reduction function which combines the results from each of these processes.
A useful concept when planning how to parallelise your code is 'work', which is roughly the total amount of CPU time that needs to be spent on running the code, and whether and how this can be subdivided between independent parallel tasks. Ideally you want to split this work equally between the available CPU cores, as we always have to wait until the last core is finished to be done, then if one has more work it will make the whole process take longer.
Multiprocessing vs multithreading
Parallelism is often closely linked to the concept of asynchronous ('async') programming. Usually each line of code you write will have to finish running, and the result be available, before the next line is run. However there are many cases with I/O where it is useful for the process to continue running the rest of the code, and at some point later check if the async line has finished and collect its result (sometimes known as futures/promises):
- Waiting for user input.
- A webpage running some processing.
- Waiting for a query to a server to return.
- Waiting for a filesystem resource to be available, or finished being written to.
In terminal code making these kind of expected waits async allows code to be more efficient, as the main process can keep going and keep the CPU busy rather than idling waiting for an external resource. Underlying this idea, operating systems supports multiple threads, which it can switch in and out of the available CPUs to try and keep them busy (this is how you can run many applications at once, even on a single core CPU). On the web this is critical, as slow communication across the network is common, and webpages would completely freeze all the time if this wasn't done asynchronously.
With parallel code you are usually taking advantage of this system and launching
multiple threads which then (hopefully) get assigned to different cores and are
executed concurrently. This distinction isn't always that important, but does explain
why you often see other async tools together with concurrency options. Note that in python
threading is for async I/O and will
not make your CPU-bound code faster, whereas multiprocessing will.
Parallelising a for loop
Let's consider an example of finding whether numbers are prime:
#![allow(unused)] fn main() { fn is_prime(n: u32) -> bool { for div in 2..n { if n % div == 0 { return false; } } true } println!("2: {} 3: {} 4: {}", is_prime(2), is_prime(3), is_prime(4)); }
This starts from a very simple way to check if a number is prime: for every integer lower
than the input (excluding 1), check whether it divides exactly. We can do this with the
modulo function %, also known as the remainder.
We can do a simple optimisation by noticing that potential divisors > n/2 will never divide exactly, and furthermore that some of these will have already been checked by dividing by 2, 3, 4 etc. These conditions meet at the square root on the input:
#![allow(unused)] fn main() { fn is_prime(int: u32) -> bool { let upper = (int as f64).sqrt().floor() as u32; for div in 2..=upper { if int % div == 0 { return false; } } true } println!("2: {} 3: {} 4: {}", is_prime(2), is_prime(3), is_prime(4)); }
A further optimisation would be to only try dividing by primes as e.g. anything divisible by 6 will also be divisible by its prime factors 2 and 3. But as this involves keeping track of a list it's a bit more complex, so we'll go with the above.
Writing a function to find whether numbers are prime, including some timing, might look like this:
use std::time::Instant; fn is_prime(int: u32) -> bool { let upper = (int as f64).sqrt().floor() as u32; for div in 2..=upper { if int % div == 0 { return false; } } true } fn main() { let size = 20000; let start = Instant::now(); let mut primes = Vec::with_capacity(size - 1); for i in 2..size { primes.push((i, is_prime(i as u32))); } // Timing let end = Instant::now(); let serial_time = end.duration_since(start).as_micros(); println!("Serial done in {}us", serial_time); // Check results look ok println!("{:?}", &primes[0..10]); }
The std::thread library gives us two tools for parallelisation:
::spawnwhich asynchronously runs the contained function in a new thread. The operating system should be able to run this thread on a different CPU core.::joinwhich waits for a spawned thread to finish, and gets the return value as a result.
So, we could try and parallelise this by spawning a new thread for every iteration of the loop, so that each integer's computation occurs on a new thread, which can potentially run in parallel:
use std::time::Instant; use std::thread; fn is_prime(int: u32) -> bool { let upper = (int as f64).sqrt().floor() as u32; for div in 2..=upper { if int % div == 0 { return false; } } true } fn main() { let size = 20000; let start = Instant::now(); let mut primes = Vec::with_capacity(size - 1); let mut threads = Vec::with_capacity(size - 1); // Spawn the threads for i in 2..size { let thread_join_handle = thread::spawn(move || { is_prime(i as u32) }); threads.push(thread_join_handle); } // Collect the results with join for (i, thread) in threads.into_iter().enumerate() { let result = thread.join().unwrap(); // join returns a result, which should be `Ok` so we can safely unwrap it primes.push((i + 2, result)); } // Timing let end = Instant::now(); let parallel_time = end.duration_since(start).as_micros(); println!("Parallel done in {}us", serial_time); // Check results look ok println!("{:?}", &primes[0..10]); }
But this is much slower than the serial version! On my laptop, this takes >2500x longer. This is due to the overhead of spawning 20k threads, which in most cases take longer than the actual computation they contain.
One solution would be to divide the total work into more equal sized chunks, and only spawn the threads once for each core we want to use:
use std::time::Instant; use std::thread; fn is_prime(int: u32) -> bool { let upper = (int as f64).sqrt().floor() as u32; for div in 2..=upper { if int % div == 0 { return false; } } true } fn main() { let size = 20000; let start_p = Instant::now(); // Split the work let threads = 4; let mut work = Vec::new(); for thread in 0..threads { let work_list: Vec<u32> = ((2 + thread)..size).step_by(threads).map(|x| x as u32).collect(); work.push(work_list); } // Spawn the threads on each chunk of work let mut thread_results = Vec::new(); for i in 0..threads { let work_for_thread = work[i].clone(); // This copy is needed, or we can use `sync::Arc` to avoid it let thread_join_handle = thread::spawn(move || { let mut work_results = Vec::new(); for j in work_for_thread { work_results.push((j, is_prime(j as u32))); } work_results }); thread_results.push(thread_join_handle); } // Collect the results with join let mut primes = Vec::new(); for thread in thread_results { let mut result = thread.join().unwrap(); primes.append(&mut result); } // Timing let end_p = Instant::now(); let parallel_time = end_p.duration_since(start_p).as_micros(); println!("Work splitting done in {}us", parallel_time); // Check results look ok println!("{:?}", &primes[0..10]); }
This gives me a speedup of about 1.5x using the four threads. As I increase the size, this gets more efficient.
When you are profiling the time taken make sure you don't include the compile time, and include optimisations. The best way is to run cargo build --release first. Then run target/release/<name>.
Adding time before your command is also helpful for seeing if multiple CPU
cores were used. Your timing may also be affected by other processes running on your machine.
Exercise Try changing the number of threads used and the total size, how does the speedup change?
We are being a bit thoughtful about the splitting of work here. The simplest thing to do would be to give each thread contiguous integers by splitting the list into four chunks:
#![allow(unused)] fn main() { let size = 20000; let threads = 4; let int_list: Vec<u32> = (2..size).map(|x| x as u32).collect(); let work_list = int_list.chunks(size / threads); }
However we know that the smaller integers will be much quicker to compute than the larger integers. So instead we interleave the work lists so that each thread has a similar number of smaller and larger integers to process, making the total work for each thread more balanced:
| Thread | Contiguous chunks | Interleaved |
|---|---|---|
| 1 | 2,3,4,5... | 2,6,10,14,... |
| 2 | 5000,5001,... | 3,7,11,15,... |
This is more efficient, but does mean the results need to be resorted at the end.
Using rayon and iterables to make this much easier
As you can see, making parallelisation work is fairly easy, but making it work
efficiently (which is the whole point) easily becomes more complex. For many problems it is better to use a parallelisation library which makes the code simpler and the parallelisation more efficient. In C++, OpenMP works well. In rust, the rayon package is good.
Working with rayon is easiest if we can rewrite the for loop with an iterator:
use std::time::Instant; fn is_prime(int: u32) -> bool { let upper = (int as f64).sqrt().floor() as u32; for div in 2..=upper { if int % div == 0 { return false; } } true } fn main() { let size = 20000; let start = Instant::now(); let integers: Vec<usize> = (2..size).collect(); let primes: Vec<(usize, bool)> = integers.iter().map(|i| { let prime = is_prime(*i as u32); (*i, prime) }).collect(); // Timing let end = Instant::now(); let serial_time = end.duration_since(start).as_micros(); println!("Serial done in {}us", serial_time); // Check results look ok println!("{:?}", &primes[0..10]); }
Any Vec can use .iter() or .into_iter() to become an iterable. Then the .map() or .for_each() methods can be used to run a function on each element.
With this recasting, rayon can simply replace .iter() with .par_iter():
use std::time::Instant; use rayon::prelude::*; fn is_prime(int: u32) -> bool { let upper = (int as f64).sqrt().floor() as u32; for div in 2..=upper { if int % div == 0 { return false; } } true } fn main() { let size = 20000; let threads = 4; rayon::ThreadPoolBuilder::new().num_threads(threads).build_global().unwrap(); let start = Instant::now(); let integers: Vec<usize> = (2..size).collect(); let primes: Vec<(usize, bool)> = integers.par_iter().map(|i| { let prime = is_prime(*i as u32); (*i, prime) }).collect(); // Timing let end = Instant::now(); let parallel_time = end.duration_since(start).as_micros(); println!("Parallel done in {}us", parallel_time); // Check results look ok println!("{:?}", &primes[0..10]); }
By default rayon uses all available cores as threads, so we set it manually to use four.
Running this and the manual work splitting approach above across a range of sizes yields the following speedups:
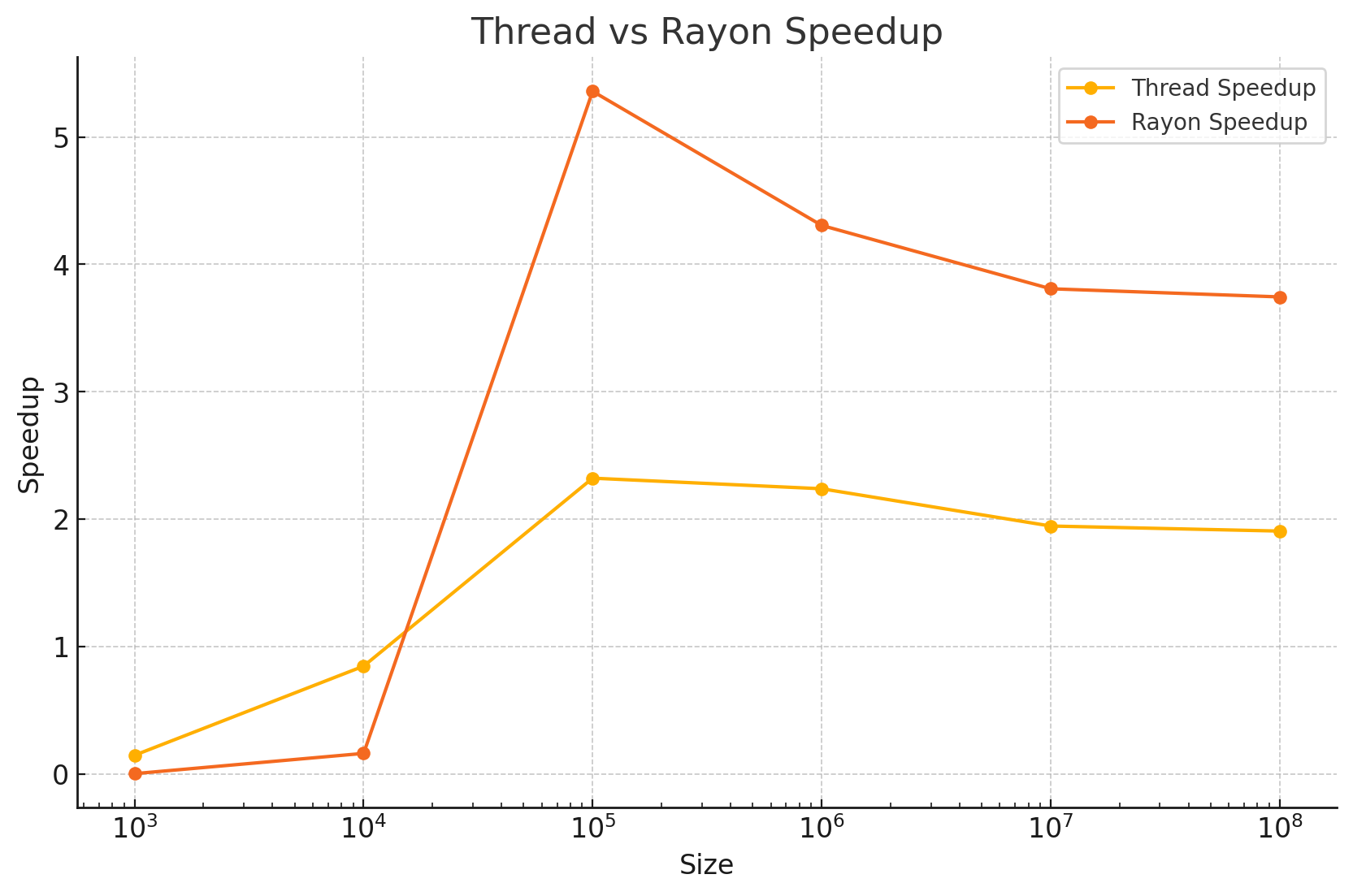
Here we can see that both methods are slower than the serial code for small amounts of work, as they are dominated by overheads. At larger problem sizes Rayon achieves close to 100% efficiency (4x speedup on 4 cores), whereas our manual approach tops out at around 50% efficiency (2x speedup on 4 threads).
Which work to parallelise?
It is common to have two possible levels over which you may wish to deploy parallelisation, consider for example this nested for loop, which estimates the proportion of prime numbers across different orders of magnitude:
fn is_prime(int: u32) -> bool { let upper = (int as f64).sqrt().floor() as u32; for div in 2..=upper { if int % div == 0 { return false; } } true } fn main() { let size = 20000; let magnitudes = vec![100000, 1000000, 10000000]; let integers: Vec<usize> = (2..size).collect(); // Test how many of the first `size` integers in each range are prime let prime_rate: Vec<f64> = magnitudes.iter().map(|mag| { integers.iter().map(|i| { if is_prime(*i as u32 + mag) { 1.0 } else { 0.0 } }).sum::<f64>() } / size as f64).collect(); println!("{:?}", prime_rate); }
Here there are two .iter() loops we could parallelise by replacing with .par_iter(),
the outer loop which runs three iterations over different magnitude ranges, and the inner
loop which runs 20k iterations over different integers.
Exercise Replace one of these at a time, then both, and compare the performance.
In general, parallelising the outer loop will give less of an overhead and result in better parallelisation efficiency. This is because the total work in each outer loop is necessarily larger than the work done in the inner loop.
However, if the outer loop does fewer iterations than you have cores, then efficiency will be limited. In this case, parallelising the inner loop, or possibly both loops, will be needed take advantage of the available resources.
An example of this kind of setup might be some stochastic simulations where you want to run ten repeats of everything in an inner loop, then have an outer loop over a small set of different parameter values. In this case, if you had 32 threads available you would probably want to parallelise both loops. This kind of setup also lends itself well to doing efficient parallelisation of a short inner loop with rust and rayon or C++ and OpenMP, then doing the outer parallelisation with R or python multiprocessing. Here you can even use different nodes for the outer parallelisation, assuming the computation is independent, so you might get up to 4x32 core nodes = 96 cores.